On dispose actuellement de chiffres sur les décès à l’hôpital et sur les admissions aux urgences. Mais comment savoir quels sont les jours où les patients ont été contaminés, alors qu’eux-même ne le savent généralement pas ? Peut-on arriver à faire ceci (
https://www.dailymotion.com/video/x2qlmuy) pour « découvrir » la courbe de contamination « cachée » derrière celle des hospitalisations ?
La réponse est en partie oui – on ne peut évidemment pas aller aussi loin que ce qui est décrit dans le film, mais on peut en effet estimer en partie ce que sont des évolutions du nombre de contaminations compatibles avec ce que l’on a observé en arrivées à l’hopital. On peut ensuite regarder si certaines propriétés de ces « contaminations compatibles » sont robustes ou non.
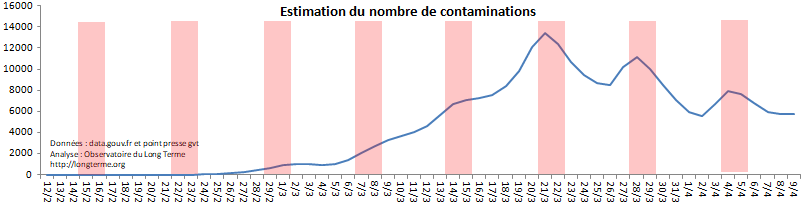
C’est ce qui a été estimé sur le graphique ci-joint. Il s’agit d’une première estimation qui méritera évidemment de faire l’objet d’analyses complémentaires. Elle ne doit pas être prise au pied de la lettre, mais elle est partagée ici pour l’intérêt de la méthode. Cette analyse très rapide vise surtout à ouvrir un débat sur cette question et les méthodes pour y répondre, plutôt qu’à trancher ce débat.
2) Un impact qui semble finalement modéré des élections du 1er tour le 14/15 mars
3) Un pic des contaminations qui est daté au 21/22 mars
4) Ce qui ressemble à un plateau depuis le retour des beaux jours (3 avril), qui traduit forcément un relâchement dans les gestes barrières et les mesures de confinement.
#restezchezvous
5) # Mise à jour le 13 avril : la baisse extrêmement forte aux urgences hier peut rendre optimisme et inverse la remarque 4. En effet il s’agit d’une des plus fortes baisses jamais constatées. Si elle se reproduit le 13 au soir, elle pourrait impliquer que les contaminations ont été pratiquement à l’arrêt et que l’effet de la chaleur sur le virus dépasse celui du relâchement du confinement.
Tous ces éléments ont une certaine robustesse, c’est à dire que les retrouve lorsque l’on fait varier les contraintes décrites ci-dessous. La encore pour les confirmer totalement, une analyse plus approfondie sera nécessaire.
Détails de la méthode utilisée :
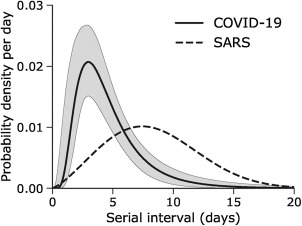
1) On part d’une courbe de probabilité de transmission de l’infection issue de recherches sur le virus telle que celle figurant ci-après
(source: https://www.sciencedirect.com/science/article/pii/S1201971220301193). Notons c1…ck la probabilité qu’une personne infectée aux dates t-1,t-2,….t-k ait besoin d’être hospitalisée à la date t et notons C=[ck,ck-1,…,c2,c1] le vecteur correspondant
2) Les hospitalisations à une date donnée correspondent à la somme des contaminations réalisées aux dates antérieures avec les probabilités de transmission du 1). Notons H=[ht0,…htn] le nombre d’hospitalisations aux dates t0 (début de l’épidémie) jusqu’à tn (date du jour).
Mathématiquement, H se calcule en apla matrice M=
[ck,ck-1,…c2,c1,0,0,….0]
[0,ck,ck-1, ,c2,c1,0 0 ]
….
[0,0….,0,ck, ,c2,c1]
et le vecteur K=[Kt0-k,Kt0-k+1,……Ktn] – qui correspond aux valeurs que nous essayons de trouver du nombre de contaminations aux dates de t0-k (la contamination peut avoir lieu jusqu’à k jours avant les premiers cas) jusqu’au jour actuel.
3) Pour estimer K, il faut inverser la matrice M. Le problème est qu’elle n’est pas inversible (il y a plus de colonnes que de lignes). En revanche, on sait définir les « pseudo inverses » de M, en suivant la méthode correspondant à la deuxième réponse dans le post suivant (
https://stats.stackexchange.com/…/extract-data-points-from-…), qui décrit également comment ces méthodes sont utilisées en traitement du signal.
Si l’on ajoute un certain nombre de contraintes (K ne contient que des nombres positifs, dont la valeur est bornée,on ne cherche que des solutions suffisamment « lisses »,…), on peut identifier des inverses possibles, qui permettent ensuite d’obtenir une estimation de K=pinv(M).H. On peut tester la solidité de certains propriétés de K en faisant varier les paramètres.
On peut arriver au même résultat en utilisant des méthodes d’optimisation numériques pour définir le vecteur K qui maximise certains critères de « beauté » tout en donnant des résultats suffisamment proches des séries d’hospitalisation observées. C’est cette deuxième méthode qui a été employée, car elle est plus souple.
Ce que font ces méthodes sur la courbe des hospitalisations, c’est (un peu) ce que font les héros de séries policières quand il partent d’une photo floues et arrivent à « zoomer et améliorer l’image » afin de découvrir par exemple la plaque d’immatriculation située « derrière le flou », comme décrit ici: https://knowyourmeme.com/memes/zoom-and-enhance . Même si elles ont des limites (on ne peut pas aller aussi loin que le film du début de ce post), ces méthodes ne sont plus de la science-fiction: https://www.youtube.com/watch?v=3RYNThid23g